SQL 的执行顺序
我们在编写一个查询语句的时候,是否考虑过sql语句的执行顺序,他是如何执行的呢?
如以下sql语句:
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >执行过程介绍
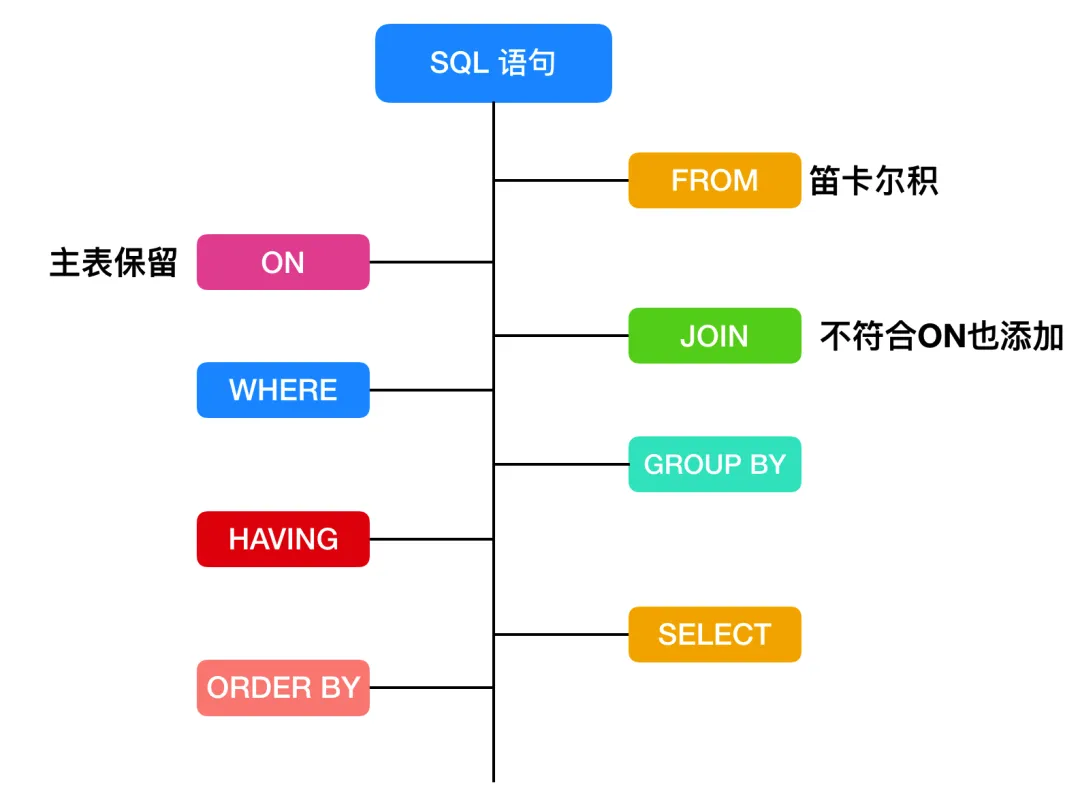
FROM
<left_table>
ON
<join_condition>
<join_type>
JOIN
<right_table>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
SELECT
DISTINCT
<select_list>
ORDER BY
<order_by_condition>
LIMIT
<limit_number>1、FROM 连接
首先,对 SELECT 语句执行查询时,对FROM 关键字两边的表执行连接,会形成笛卡尔积,这时候会产生一个虚表VT1(virtual table)
首先先来解释一下什么是笛卡尔积
现在我们有两个集合 A = {0,1} , B = {2,3,4}
那么,集合 A * B 得到的结果就是
A * B = {(0,2)、(1,2)、(0,3)、(1,3)、(0,4)、(1,4)};
B * A = {(2,0)、{2,1}、{3,0}、{3,1}、{4,0}、(4,1)};上面 A B 和 B A 的结果就可以称为两个集合相乘的 笛卡尔积
我们可以得出结论,A 集合和 B 集合相乘,包含了集合 A 中的元素和集合 B 中元素之和,也就是 A 元素的个数 * B 元素的个数
再来解释一下什么是虚表
在 MySQL 中,有三种类型的表
-
一种是永久表,永久表就是创建以后用来长期保存数据的表
-
一种是临时表,临时表也有两类,一种是和永久表一样,只保存临时数据,但是能够长久存在的;还有一种是临时创建的,SQL 语句执行完成就会删除。
-
一种是虚表,虚表其实就是视图,数据可能会来自多张表的执行结果。
2、ON 过滤
然后对 FROM 连接的结果进行 ON 筛选,创建 VT2,把符合记录的条件存在 VT2 中。
3、JOIN 连接
第三步,如果是 OUTER JOIN(left join、right join) ,那么这一步就将添加外部行,如果是 left join 就把 ON 过滤条件的左表添加进来,如果是 right join ,就把右表添加进来,从而生成新的虚拟表 VT3。
4、WHERE 过滤
第四步,是执行 WHERE 过滤器,对上一步生产的虚拟表引用 WHERE 筛选,生成虚拟表 VT4。
WHERE 和 ON 的区别
如果有外部列,ON 针对过滤的是关联表,主表(保留表)会返回所有的列;
如果没有添加外部列,两者的效果是一样的;
WHERE 和 ON 的应用
对主表的过滤应该使用 WHERE;
对于关联表,先条件查询后连接则用 ON,先连接后条件查询则用 WHERE;
5、GROUP BY
根据 group by 字句中的列,会对 VT4 中的记录进行分组操作,产生虚拟机表 VT5。果应用了group by,那么后面的所有步骤都只能得到的 VT5 的列或者是聚合函数(count、sum、avg等)。
6、HAVING
紧跟着 GROUP BY 字句后面的是 HAVING,使用 HAVING 过滤,会把符合条件的放在 VT6
Having与Where的区别
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
注意:
- 1、HAVING子句必须位于GROUP BY之后ORDER BY之前。
- 2、WHERE语句在GROUP BY语句之前;SQL会在分组之前计算WHERE语句。
- 3、HAVING语句在GROUP BY语句之后;SQL会在分组之后计算HAVING语句。
示例 :
select 类别, sum(数量) as 数量之和 from A group by 类别 having sum(数量) > 18
select 类别, SUM(数量)from A where 数量 > 8 group by 类别 having SUM(数量) > 107、SELECT
第七步才会执行 SELECT 语句,将 VT6 中的结果按照 SELECT 进行刷选,生成 VT7
8、DISTINCT
在第八步中,会对 TV7 生成的记录进行去重操作,生成 VT8。事实上如果应用了 group by 子句那么 distinct 是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
9、ORDER BY
应用 order by 子句。按照 order_by_condition 排序 VT8,此时返回的一个游标,而不是虚拟表。sql 是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。